Wat is Linear Regression
Met behulp van lineaire regressie is het mogelijk om een model te ontwikkelen dat de relatie beschrijft tussen onafhankelijke variabelen (X) en de afhankelijke variabele (Y). Dit kan bijvoorbeeld toegepast worden in situaties zoals:
- Het voorspellen van de optimale dosering van medicatie op basis van het gewicht van een patiënt
- Het voorspellen van een salaris op basis van een uurtarief
In een lineair regressiemodel worden vaak verschillende termen gebruikt om de variabelen te benoemen:
- Onafhankelijke variabelen, ook wel bekend als verklarende variabelen, inputs of X.
- Afhankelijke variabele, ook wel de output of Y genoemd.
Over het algemeen wordt lineaire regressie in twee complexiteitsniveaus onderverdeeld:
- Eenvoudige lineaire regressie (univariate lineaire regressie): Hierbij wordt slechts één onafhankelijke variabele gebruikt om de afhankelijke variabele te voorspellen.
- Meervoudige lineaire regressie (multivariate lineaire regressie): Hierbij worden meerdere onafhankelijke variabelen gebruikt om de afhankelijke variabele te voorspellen.
Met behulp van lineaire regressie kun je dus een relatie onderzoeken tussen verschillende variabelen, zoals de relatie tussen buitentemperatuur en het aantal verkochte schaatsen, of tussen iemands leeftijd en het aantal speelfilms dat die persoon kijkt.
Formule van Linear Regression
De formule voor lineaire regressie kan als volgt worden weergegeven:
y = a1x1 + a2x2 + ... + anxn + b + ε
Hierbij worden de termen als volgt gedefinieerd:
- y: De afhankelijke variabele
- b: De interceptcoëfficiënt, die de waarde vertegenwoordigt waarbij de regressielijn de y-as kruist als alle X-variabelen nul zijn.
- a1 tot an: De regressiehellingcoëfficiënten die de impact van elke onafhankelijke variabele op de afhankelijke variabele aangeven.
- x1 tot xn: De onafhankelijke variabelen.
- ε: De afwijking (of fout), die het verschil vertegenwoordigt tussen de werkelijke waarde van de afhankelijke variabele en de voorspelde waarde.
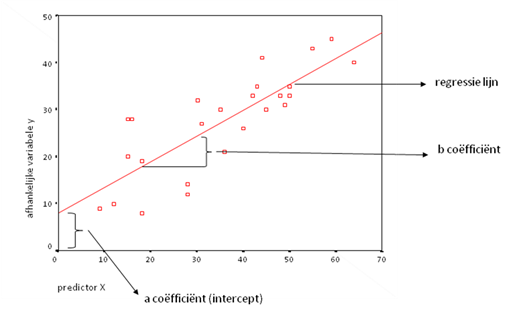
Elke set waarden van de onafhankelijke variabelen die leidt tot een specifieke waarde van de afhankelijke variabele wordt een observatie genoemd. Bijvoorbeeld, in een medisch onderzoek zouden de observaties de verzamelingen van metingen zijn die zijn uitgevoerd bij verschillende patiënten. De afwijking tussen de werkelijke en voorspelde waarden wordt gedefinieerd als de residu of fout.
Voorbeeldcase: Pieters Datingwebsite
Pieter beheert een E-commerce website. Hij wil onderzoeken hoeveel klanten gemiddeld per jaar besteden op basis van de duur van hun lidmaatschap. Pieter verstrekt de data, en bij visualisatie ziet het er als volgt uit:
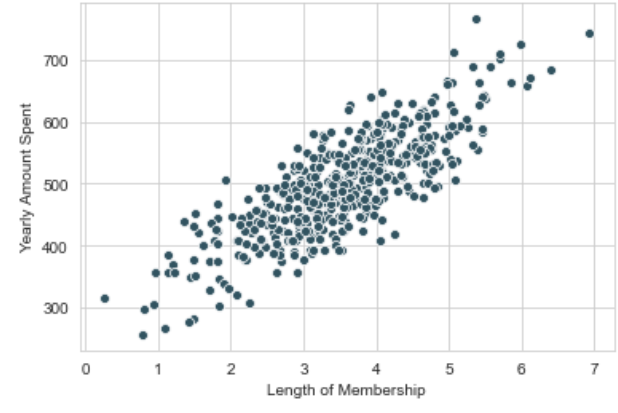
Met het blote oog is duidelijk een patroon te zien in de data punten. Ze vertonen een correlatie, zoals te zien is. Nu kunnen we een lineaire regressielijn construeren om de gemiddelde uitgaven te bepalen. Dit ziet er als volgt uit:
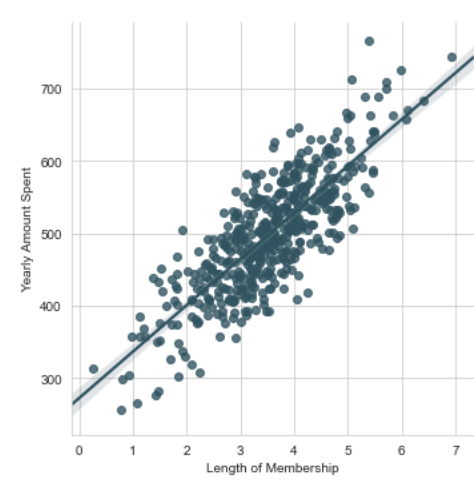
De regressielijn representeert het gemiddelde bedrag dat wordt uitgegeven. Stel ik vraag je: "Hoeveel besteedt iemand gemiddeld wanneer hij 4,5 jaar lid is van de website?" Dan is het antwoord ongeveer 550 euro. De regressielijn vormt dus de kern, en het algoritme gebruikt deze als leidraad om consequent resultaten weer te geven.